I’m running an all-AI team of seven programmers and a manager. I provide guidance, strategic direction, and surgical intervention; the seven programmers handle their workloads; the manager coordinates. It works really well.
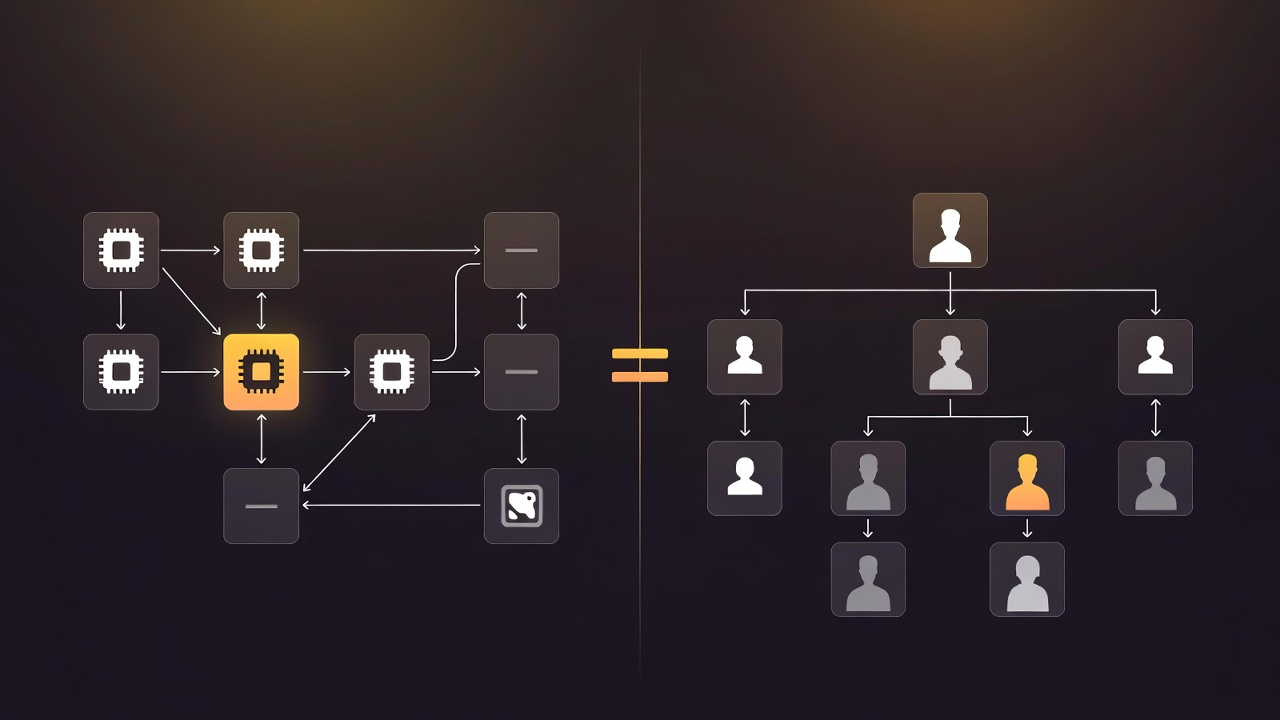
Why does it work so well? The short version: I didn’t invent anything. I just noticed that an agentic coding team is both a software architecture problem and a team management problem at the same time, and applied known best practices from both.
The Architecture
The system is a microservices topology. Seven domain-specialist agents — each with distinct responsibilities like data, infrastructure, and web — plus a manager agent. Each runs in its own git worktree. Each owns its slice of the codebase and nothing else.
If you’ve built or managed microservices, everything about how these agents interact will be familiar.
It’s Just Microservices
Strong ownership boundaries. Agents don’t touch each other’s code. The data agent owns data. The infra agent owns infra. No exceptions. This isn’t just an organizational preference — it’s what eliminates merge conflicts. Since each agent manages its own house, parallel work rarely collides. When it does, it’s trivial: two agents added terms to the same shared dictionary, and the resolution is to accept both.
Callee-defined contracts. When one agent consumes another’s output, the provider defines the canonical structure. The consumer writes its own ingestion adapter. This is standard API design — the same reason you don’t let downstream services dictate your schema. It means agents can evolve their internal implementations freely without breaking consumers, and it eliminates the cascading dependency problem where one team’s needs ripple across the entire system.
A proposal system for cross-cutting changes. If an agent needs something from another domain or wants to suggest a project-wide standard, it writes a detailed proposal. It doesn’t just make the change. This is the equivalent of an RFC process. Proposals sit in a queue until the sprint cycle completes, then the manager processes them. Most resolve naturally — parallel work addressed the need, or the requesting agent figured out an alternative. What remains is genuine cross-cutting work that deserves deliberate attention.
It’s Also Just Team Management
The same system maps cleanly to established team management principles, which shouldn’t be surprising — microservices organizations and high-functioning engineering teams converge on the same patterns for the same reasons.
Domain ownership over task assignment. An agent that owns a domain builds context over successive sprint cycles and makes increasingly better decisions within that domain. An agent that gets random tickets from a shared backlog starts from scratch every time. This is the same reason you don’t rotate engineers across teams weekly.
Documentation as a first-class team member. A dedicated documentation agent means docs actually get written — not as an afterthought, not as a checkbox, but as someone’s entire job. This is the thing every human engineering team knows they should do and never does because documentation always loses the priority fight against feature work. When it’s a dedicated agent, there’s no priority fight.
Broad autonomy with surgical intervention. Let agents run. Correct when they drift — fix a testing philosophy, catch an architectural conflation, redirect a misguided approach. This is servant leadership: you invest heavily in guardrails, standards, and governance upfront so you can stay out of the way during execution. The alternative — micromanaging every agent’s decisions — defeats the purpose of having agents at all.
Retrospectives drive process improvement. The /insights report feeds directly back to the manager agent as instructions for refining its operating model. Closed-loop process improvement, running automatically.
The Sprint Cycle
The manager agent creates and assigns work as GitHub issues. Each agent picks up its unblocked tasks and executes until it’s out of work, then runs a documentation cleanup and shuts down. The manager waits for all agents to finish, reviews what each branch accomplished, identifies any merge risks, and proposes a merge order that minimizes execution risk. After merging (running all tests after each), it processes the proposals.
Most proposals fall into predictable categories. About a third are already addressed — the agent needed functionality that another agent built in parallel. Many are best-practice promotions: “this pattern worked well in my domain, everyone should adopt it.” These get added to the shared project instructions. What remains becomes either a GitHub issue for the next cycle or, in a small minority of cases, something that needs my judgment. That last category — the cross-cutting architectural decisions where an error would propagate widely — is where I focus my time. Everything else runs without me.
The cycle then starts over. Each agent pulls its new set of unblocked tasks and starts cranking.
Why the Microservices Framing Matters Beyond Analogy
This isn’t just a metaphor. The microservices framing gives you concrete architectural benefits.
The system is easy to restructure. Adding a new agent is straightforward: stand up a worktree, define its domain, point it at its issues. Splitting an agent that’s gotten too broad works the same way you’d decompose a service that’s taken on too many responsibilities. Agents that run out of relevant work just stop getting tasks — you don’t delete them, they simply go idle. The topology evolves with the project the same way a service mesh evolves with the product.
It solves the context window problem architecturally rather than technically. Each agent only needs deep understanding of its own domain plus the contract interfaces with adjacent domains. You’re not fighting token limits by trying to cram an entire system into one conversation — you’ve decomposed the cognitive load the same way you’d decompose a monolith. Bounded contexts from domain-driven design, applied to AI agents.
It makes the system legible. When something goes wrong, you know which agent owns that domain and you can review its work in isolation. When the system needs to grow, you know where to add capacity. The org chart is the architecture diagram.
The Punchline
None of the individual pieces here are new. Ownership boundaries, callee-defined contracts, RFC processes, sprint cycles, servant leadership, dedicated documentation teams, domain-driven decomposition — these are all established practices with decades of refinement behind them. The insight is just that when you’re building with AI agents, you’re doing team design and system design simultaneously, and the same patterns that work for human engineering organizations work here. That shouldn’t be surprising, but most agentic coding setups I see treat agents as souped-up autocomplete rather than as team members that need organizational structure to be effective.
The value is shifting from writing code to designing the system that writes code. And it turns out that system looks a lot like a well-run engineering team.